こんにちは
Blenderをバックグラウンドで起動し,モデルを読み込んでレンダリングした時の備忘録です.
参考文献
まずは公式に目を通そう!
docs.blender.org
こんな記事よりGeminiに聞いた方が正確...
gemini.google.com
開発環境
- Windows 11 (25H2, 26200.8737)
- Blender 5.0.1
- docker desktop 4.68.0 (223695)
- Ubuntu-24.04 (WSL2)
- python 3.11.9
- Blender 5.0.1
ホスト(Windows11)/ゲスト(Ubuntu-24.04)の組み合わせですが,BlenderとPythonが使える環境なら何でもOK.
Windows側のBlenderで*.blendの環境を構築し,Ubuntu側のBlenderでレンダリングする.
敢えてBlenderのバージョンに差をつけてみたら地獄を見た.
バージョン3以下と4以降でファイル形式が結構変わったっぽいから気を付けて.
何も考えたくないならバージョンは合わせるのがおススメ.
Windows: *.blendの構築
Windows側のBlenderでGUIを利用しながらレンダリング環境を構築する.
ここではテスト用のセットアップを載せるけど,自分の好きなように設定すればいい.
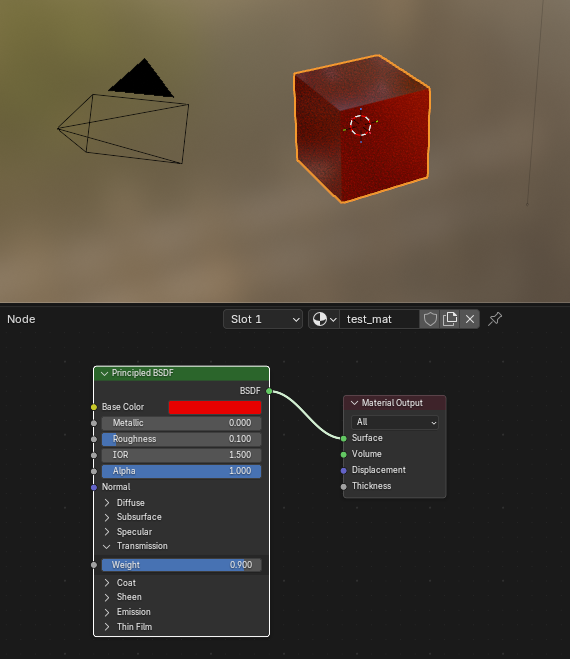
- 初期キューブに適当なマテリアルを割り当てる
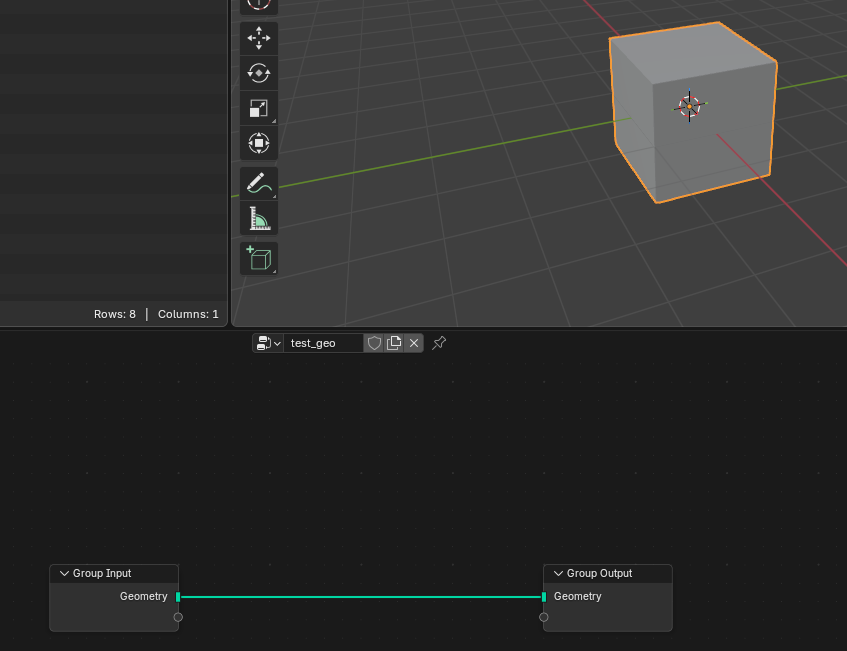
- 初期キューブに適当なGeometry Nodesを割り当てる
- 初期キューブを削除
マテリアルとGeometryNodesだけの関係だからね.
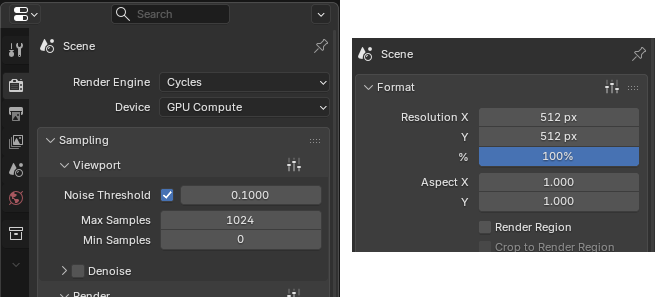
もう用済みってわけよ. - レンダリングの設定
シーンと解像度を好きなように設定.
今回はテストなのでCycles/GPU Computeにしてみた.
どうやらバックグラウンドだと,スクリプト側から設定しないとGPUを使わないっぽい?
よく分かってない.
- test.blendとして保存
これをバックグラウンドで利用する.
作成した test.blend を適切なフォルダに移動させる.
併せてテスト用のモデル(test.ply)も同じフォルダに移動させた.
Ubuntu: レンダリング実行用のPython作成
BlenderのPython実行は blender -b -P test.py です.
-b: --background
-P: --python
ダブルダッシュ以降はPython用の引数として認識できるみたい.
これを利用してファイルの受け渡しを行う.
実行方法: blender -b -P ./test.py -- test.blend test.ply output.png
レンダリング結果
GPUはスクリプト側から設定しないと使ってくれなかった.

感想
バッチ処理が捗りそう.
3Dモデルアップロード → Blenderバックグラウンド起動 → レンダリング → Webサイトに表示
のような自動化が実現できるかもね.
おまけ: Blender付属Pythonを触ってみた
Windows11側にインストールしてあるBlender経由でPythonを使った時のメモ.
Windows環境でPythonを使いたいけど,Pythonをインストールしたくない時に使えるかも....
実質,SteamでPythonをインストールできるってコト!?
store.steampowered.com
BlenderのPythonの確認
Windowsなら C:\Program Files\Blender Foundation\Blender 5.0\5.0\python\bin\python.exe に入ってるはず.
これを叩くだけではつまらないので,何がプレインストールされているか見てみる.
print("TEST") import numpy as np print(np.arange(10)) import pkgutil for m in sorted(pkgutil.iter_modules(), key=lambda x: x.name): print(m.name)
このスクリプトの実行結果がコレ.
割と色々あるな.
Blender 5.0.1 (hash a3db93c5b259 built 2025-12-16 01:32:30) TEST [0 1 2 3 4 5 6 7 8 9] Cython MaterialX OpenImageIO PyOpenColorIO __future__ __hello__ __phello__ _aix_support _animsys_refactor _asyncio _bl_console_utils _bl_i18n_utils _bl_rna_utils _bl_text_utils _bl_ui_utils _blendfile_header _bootsubprocess _bpy_internal _bpy_restrict_state _bpy_types _bz2 _collections_abc _compat_pickle _compression _console_python _console_shell _ctypes _decimal _distutils_hack _elementtree _graphviz_export _hashlib _keyingsets_utils _lzma _markupbase _msi _multiprocessing _osx_support _overlapped _py_abc _pydecimal _pyio _queue _rna_info _rna_manual_reference _rna_xml _sitebuiltins _socket _sqlite3 _ssl _strptime _threading_local _uuid _weakrefset _zoneinfo abc addon_utils aifc antigravity argparse ast asynchat asyncio asyncore attr attrs autopep8 base64 bdb bisect bl_app_override bl_app_template_utils bl_keymap_utils bl_operators bl_pkg bl_ui blend_render_info bpy bpy_extras bz2 cProfile calendar cattr cattrs certifi cgi cgitb charset_normalizer chunk cmd code codecs codeop collections colorsys compileall concurrent configparser contextlib contextvars copy copyreg crypt csv ctypes curses cycles cython dataclasses datetime dbm decimal difflib dis distutils doctest email encodings ensurepip enum fastjsonschema filecmp fileinput fnmatch fractions freestyle ftplib functools genericpath getopt getpass gettext glob gpu_extras graphlib gzip hashlib heapq hmac html http hydra_storm idna imaplib imghdr imp importlib inspect io io_anim_bvh io_curve_svg io_mesh_uv_layout io_scene_fbx io_scene_gltf2 ipaddress json keyingsets_builtins keyword lib2to3 linecache locale logging lzma mailbox mailcap mesonbuild mimetypes modulefinder msilib multiprocessing netrc nntplib node_wrangler nodeitems_builtins nodeitems_utils ntpath nturl2path numbers numpy opcode openvdb operator optparse os oslquery parameter_editor pathlib pdb pickle pickletools pip pipes pkg_resources pkgutil platform plistlib poplib pose_library posixpath pprint profile pstats pty pxr py_compile pyclbr pycodestyle pydoc pydoc_data pyexpat pyximport queue quopri random re reprlib requests rigify rlcompleter rna_keymap_ui rna_prop_ui runpy sched secrets select selectors setuptools shelve shlex shutil signal site sitecustomize smtpd smtplib sndhdr socket socketserver sqlite3 sre_compile sre_constants sre_parse ssl stat statistics string stringprep struct subprocess sunau symtable sysconfig tabnanny tarfile telnetlib tempfile textwrap this threading timeit token tokenize tomllib trace traceback tracemalloc tty types typing typing_extensions ui_translate unicodedata unittest urllib urllib3 uu uuid venv viewport_vr_preview warnings wave weakref webbrowser winsound wsgiref xdrlib xml xmlrpc zipapp zipfile zipimport zoneinfo zstandard Blender quit
Pixar系もあって,さすがBlenderって感じ.
OpenUSDも簡単に使えそう.
鉄板ネタ
Blender付属Pythonで見つけた鉄板ネタをやってみた.
this
ja.wikipedia.org
.\blender.exe -b --python-expr "import this" Blender 5.0.1 (hash a3db93c5b259 built 2025-12-16 01:32:30) The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those! Blender quit
antigravity
.\blender.exe -b --python-expr "import antigravity"
xkcd.com
gpu, gpu_extras
Blenderのビューポートの描画処理に介入できる.
これはタイムラインを再生させると円が周るやつ.
import bpy import gpu import math from gpu_extras.batch import batch_for_shader shader = gpu.shader.from_builtin('UNIFORM_COLOR') def draw(): t = bpy.context.scene.frame_current * 0.05 verts = [] for i in range(50): a = i * math.pi * 2 / 50 + t verts.append(( math.cos(a) * 3, math.sin(a) * 3, 0 )) batch = batch_for_shader( shader, 'LINE_LOOP', {"pos": verts} ) shader.bind() shader.uniform_float( "color", (1, 1, 0, 1) ) batch.draw(shader) bpy.types.SpaceView3D.draw_handler_add( draw, (), 'WINDOW', 'POST_VIEW' )
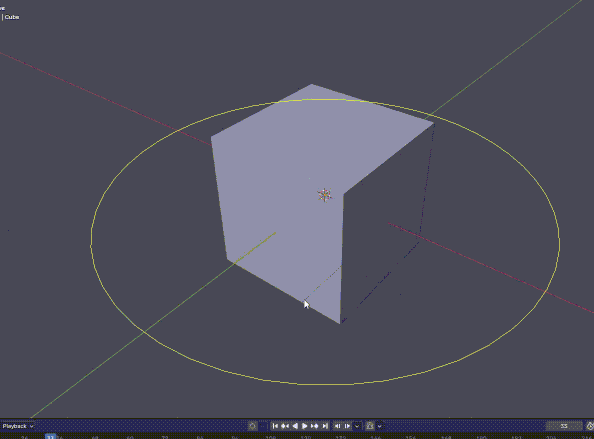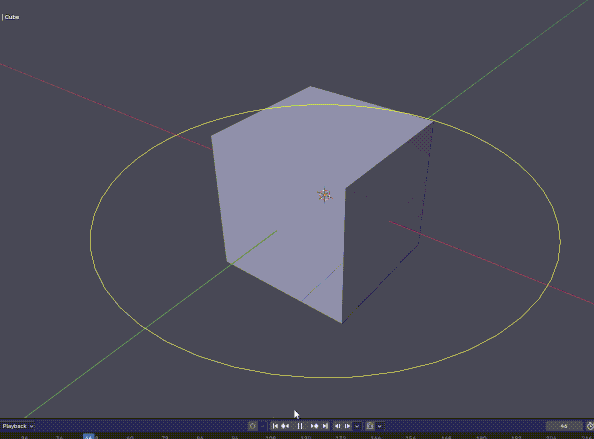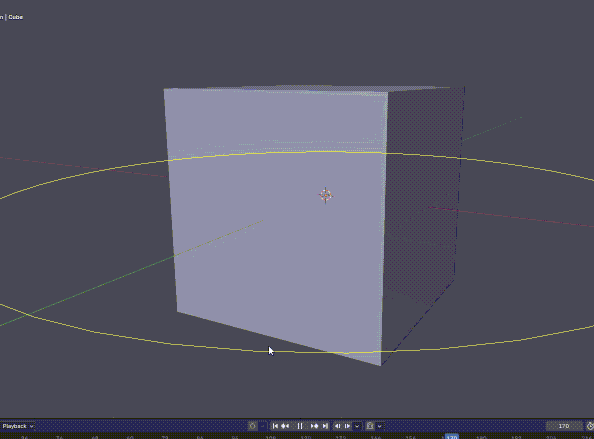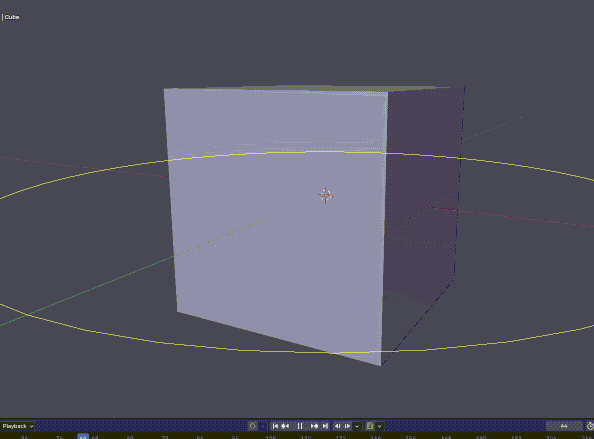
Blenderで色々できそうだね!

 - 米津玄師 (特典なし)")